浏览器
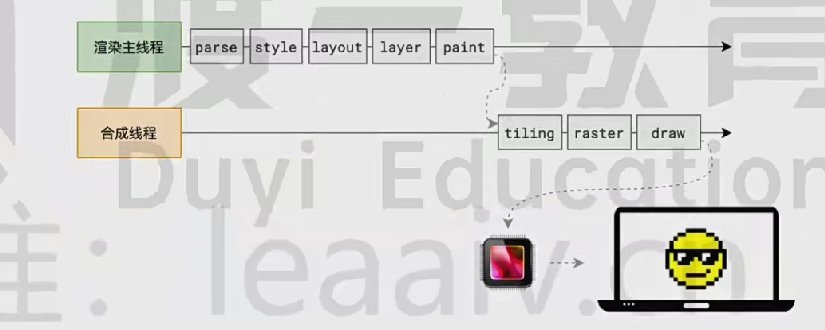
1. 浏览器渲染流程
下文中每一步,都会有一个产出,然后执行下一步
(1) 解析HTML
- 浏览器收到字节数据(0101),转为字符串数据(
<a>123</a>),然后浏览器通过词法分析转化为标记(即标记化)。因为不标记化的话,浏览器就会认为字符串数据像一篇没有分段的文章,通过标记化可以知道哪些是标签,哪些是字符串,然后构建出DOM树。这些都是渲染主线程做的事情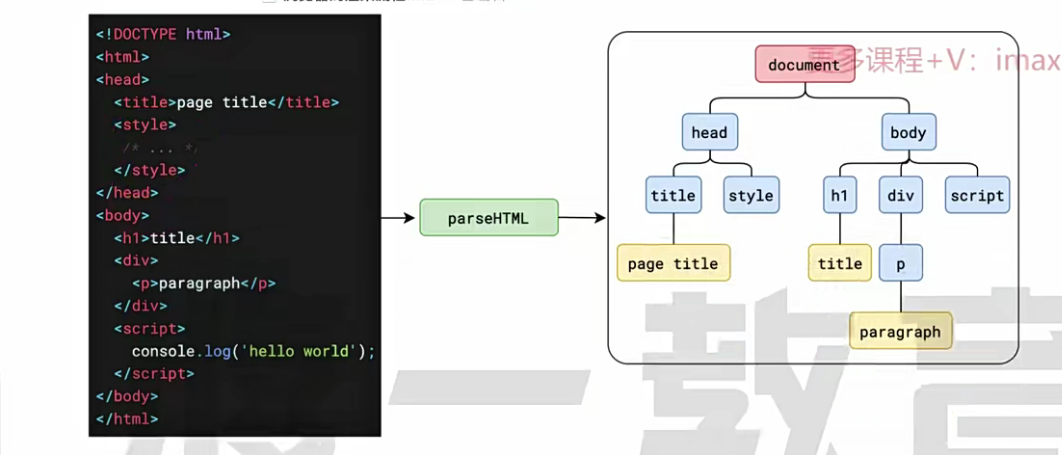
- 为了提高解析效率,浏览器在开始解析前,会启动
预解析线程,率先下载HTML中外部的CSS、JS文件(这些都在网络线程中下载),在本线程解析CSS,解析完了以后还给主线程,这就是CSS不会堵塞HTML解析的根本原因。而JS则需要甩给主线程执行。 - CSS的解析在经历了字节数据、字符串、标记化后,最终会形成一颗
CSSOM树 - 如果主线程解析到JS位置,会停止解析HTML,转而执行JS直到执行完毕(防止某些JS需要修改DOM树),这就是JS堵塞HTML解析的根本原因,所以为了加快首屏渲染,JS就应该放到body的底部。
- 总结,在这一步中得到了
DOM树和CSSOM树
(2) 样式计算
- red会变成rgb(255,0,0);
- 相对单位会变成绝对单位。
- 会对所有的DOM节点计算出所有的样式属性值,没写的大概率是默认值。
- 这一步完成以后,两棵树就会合并为一颗带有样式的DOM树
(3) 布局
- 根据DOM计算样式计算出一个布局树(Layout树)
- 布局树上每个节点都会有他在页面上的x、y坐标以及盒子大小
- 布局树和DOM树并非一一对应,布局树只有那些可见的节点信息,布局树直接决定了显示出来的页面长什么样子
- 比如伪元素存在布局树,但不存在DOM树;display:none的存在于DOM树,不存在布局树
(4) 分层
- 在某一层修改以后,可以只对这一层做更新,提高渲染效率
- 为了确定哪些元素需要放在哪一层,主线程需要遍历整个布局树来创建一颗层次树
(5) 生成绘制指令
- 主线程会为每个层单独产生绘制指令集,用于描述这一层的内容如何绘制,类似于Canvas指令
- 生成绘制指令集以后,渲染主线程的工程告一段落;主线程会将指令集交给合成线程完成
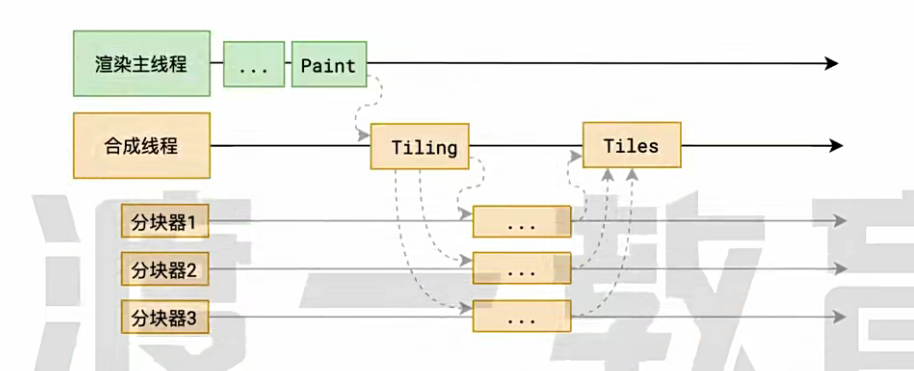
(6) 分块
- 合成线程会把每个图层分成小块
- 此时它会从线程池中拿取多个线程来完成分块工作
- 最后再汇总都按合成线程上
(7) 光栅化
- 把每一块变成位图
- 每个块精确到像素点,每个点都是什么颜色
- 这里由合成线程将块信息交给GPU进程以极高的速度完成光栅化
- GPU进程会开启多个线程来完成光栅化,并优先处理靠近视口区域的块
(8) 绘制
- 所有的块被栅格化以后,合成线程会拿到每个层、每个块的位图,从而形成一个个
quad(指引)信息 - 指引会表示出每个位图应该画到哪个位置以及考虑旋转缩放等变形,这些发生在合成线程,与渲染无关,这就是
transform效率高的本质原因 - 合成线程会通过IPC向浏览器进程提交一个渲染帧,这个时候可能有另外的合成帧被浏览器进程的UI线程提交以改变浏览器的UI。这些合成帧最后都发送到GPU完成屏幕成像
2. 资源提示关键词
- html渲染的时候遇到script标签会开始等待标签下载和执行
- js可以访问DOM也可以访问CSSOM,所以css可能会根据文档中外部样式和脚本的顺序阻止解析,举例:js中访问和使用CSSOM,就得等到CSS文件被下载解析且CSSOM可用。如果CSSOM处于未可用状态,则会阻塞js的执行。
- async - 下载完了立即执行;defer - 下载完了等待DOM树构建完成再执行
- preload - 预先加载js或者css,在随后的页面渲染中,一旦需要立即调用
- 允许浏览器设置资源优先级,优化某些资源的交付
- 浏览器确定资源类型,判断将来是否可以重用
- 浏览器通过as属性定义的内容来确定请求是否符合内容安全策略
- 浏览器可以根据资源类型发送合适的accept头
<link rel="preload" href="style1.css" as="script">
<link rel="preload" href="style1.css" as="style">
<link rel="preload" href="style1.css" as="image">
<link rel="preload" href="style1.css" as="font">
<link rel="preload" href="style1.css" as="document">
<!-- ... -->- prefetch - 利用浏览器空闲时间加载未来可能用到的非首页的其他资源,以便加快后续页面的首屏速度。
- 用法和preload一样,prefetch加载的资源可以放入缓存至少五分钟,页面跳转的时候未完成的请求也不会中断。
- dns-prefetch,允许用户浏览时在后台执行DNS查找,减少延迟
<link rel="dns-prefetch" href="//fonts.googleapis.com">3.浏览器缓存
可以做缓存的地方:数据库缓存、CDN缓存、代理服务器缓存、浏览器缓存、应用层缓存
浏览器缓存
- 浏览器发送HTTP请求,有缓存读缓存,没有缓存向服务器发送请求,获得资源以及缓存标识并存储于缓存中。
按照缓存权重:Service Worker > Memory Cache > Disk Cache > Push Cache
Service Worker
- 运行在浏览器背后的独立线程,可以用来实现缓存
- 传输协议必须是HTTPS,因为Service Worker涉及到请求拦截
Memory Cache(浏览器自己的行为)
- 内存中的缓存,速度比磁盘块,缓存虽然读取高效,但是持续很短,一旦关闭浏览器Tab就释放了
- 保证了一个页面中如果有两个相同的请求
Disk Cache(浏览器自己的行为)
- 缓存在硬盘上
- 浏览器自动清理的时候用特殊算法把“最老的”或者“过时的”资源删除
Push Cache
- HTTP/2新增的内容
- 当以上三种缓存都没有命中,它才会被使用
强缓存和协商缓存
- 都属于Dick Cache或者HTTP Cache里面的一种
强缓存
(1) 强制缓存是指客户端请求后先访问缓存数据库查看缓存是否存在,不存在就请求服务器再写入缓存数据库
(2) 强缓存满足条件的时候不请求后台
(3) 强制缓存直接减少请求数,是提升最大的缓存策略
- Expires
- 基于HTTP1.0,表示缓存时间,是一个绝对的时间(Thu, 10 Nov 2017 08:45:11 GMT)
- 用户修改本地时间会导致缓存失效
- 时间字符串太复杂,多空格或者少个字母都会非法属性导致失效
- Cache-control
- 从HTTP1.1以后Expires逐步被
Cache-control:max-age=2592000取代 - 上述中的
max-age可以替换为no-cacheno-storepublic等等参数。 - 这些值混着使用的时候会存在一个优先级的问题。
- 从HTTP1.1以后Expires逐步被
- 强制缓存失效后需要使用协商缓存
协商缓存
(1) 只要资源没有更新,哪怕时间失效了,也会使用缓存
(2) 每次都会请求后台,如果满足条件返回304(资源无更新)
(3) Last-Modified(最后一次修改时间)& If-Modified-Since(记录的修改时间)
- 请求将上次从服务器拿到的Last-Modified写入请求头的If-Modified-Since,如果这个If-Modified-Since与服务器的Last-Modified相同,就304;否则就代表修改了,响应200
- 缺陷:如果资源更新速度是秒以下单位,该缓存不能使用,因为时间最低是秒
- 缺陷:如果文件是通过服务器动态生成的,该方法更新时间永远是生成的时间,尽管文件没有变化,但是起不到缓存的作用
- 随后在http1.1出现了Etag & If-None-Match
(4) Etag & If-None-Match(基于HTTP/1.1)
- Etag存储文件的特殊标识(一般是一个hash值)
- 流程与上述相同,请求的时候吧Etag给请求头的If-None-Match,然后比对
- 性能上Etag要计算hash,所以性能要低一些
- 如果都定义了Last-Modified和Etag都定义了,Etag优先级更高。
实际开发的时候 Expires和Cache-control一起用,Last-Modified & If-Modified-Since以及Etag & If-None-Match也是一起用。
结论:
- 对于频繁变动的资源,使用Cache-Control:no-cache(每次请求时也必须向服务器发送请求以验证资源是否已更新),然后配合Last-Modified或者Etag来验证资源是否有效。不能减少请求次数,但减少了不必要的数据传输。
- 不常变化的资源,给他们Cache-Control设置一个很大的max-age = 31536000(一年)来强制缓存,同时给文件名添加Hash解决更新问题。当文件修改以后,以前的缓存并非失效了,只是不再使用了。
网络
1.get和post的区别
从http协议的角度来说,get和post他们只是请求行中的第一个单词,除了语义不同,其实没有本质的区别,之所以在实际开发产生各种区别,主要是由于浏览器的默认行为造成的:
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST请求的传递信息量是没有限制的,适合传输大量数据
- GET 请求只能传递ASCII数据,遇到非ASCII数据需要进行编码;POST请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用GET请求,至少不应该放到path中
- 刷新页面时,若当前的页面是通过POST请求得到的,则浏览器会提示用户是否重新提交。若是GET 请求得到的页面则没有提示
- GET 请求的地址可以被保存为浏览器书签,POST不可以
2.cookie
客户端和服务端传输使用http协议,但是是无状态的:服务器不知道这一次请求的人跟之前登录的成功的是不是一个人
组成
- key:键
- value:值
- dommain:域。表示cookie属于哪个网站
- path:路径,表达这个cookie是属于该网站的那个路径
- secure:是否使用安全传输协议
- expire:过期时间
- httponly:如果设置了这个值,表示这个cookie只能用于传输,不允许js获取cookie
什么时候生效
cookie,如果一个cookie同时满足以下条件,则这个cookie会被附带到请求中
- cookie没有过期
- cookie中的域和这次请求相匹配
- 比如cookie的域是yuanjin.tech,则可以匹配yuanjin.tech、www.yuanjin.tech、blogs.yuanjin.tech等
- 而www.yuanjin.tech只能匹配www.yuanjin.tech结尾的域
- 不在乎端口,只要域匹配就行
- path路径要匹配,比如cookie的path是/news,则可以匹配以/news开头的路径
- 验证cookie的安全传输
- 如果cookie的secure属性是true,则必须使用https协议,否则不会发送cookie
- false的时候,https和http皆可
如何设置cookie
- 服务器端设置cookie,
Set-Cookie:cookie - 键=值;path=?(不设置的时候默认是/);domin=?(不设置的时候默认是当前);expire=?;max-age=?;secure;httponly
- 删除cookie(比如修改密码)服务端可以选择set-cookie:token=;domain=yuanjin.tech;path=/;max-age=-1,且domain和path一定要相同
- 客户端也可以设置cookie
- document.cookie = "键=值;path=?;domain=?;expires=?;max-age=?;secure;"
3.cookie、sessionStorage、localStorage
- cookie的兼容性较好,所有浏览器都支持。如果响应头中出现set-cookie的字段时候,浏览器会自动保存cookie的值;发送请求会匹配cookie到请求头中。
- Storage需要手动存储,手动发送。这件事交给前端开发者,让恶意攻击者难以针对登录状态攻击
- cookie大小是有限制的,每个4KB左右,一个域下的总量为4M,sessionStorage通常5MB,localStorage通常5-10MB
- cookie与domain、path关联,而storage只与domain相关联
4.加密与解密
- 对称加密双方都可以解密,如DES等
- 非对称加密只有一方可以解密,如RSA等
- 摘要,通过函数将任意长度数据转化为一个固定场数据串,不可逆,可以用来校验内容有没有被篡改,常用语数字信封
5.JWT的令牌格式
- token 分为三段,分别是header、payload、signature
- header标识签名算法和令牌类型;payload标识主体信息,包括令牌过期时间、发布时间、发行者、内容等;signature是使用特定的算法对前面两部分进行加密,得到加密的结果。
- 如果攻击者修改了前两个部分,就会导致第三部分对应不上,使得token失效
- 因此,在密钥不泄露的前提下,一个验证通过的token是值得信任的。
// Authorization:
// Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6ImM2MTJiOWFmLWY3MTQtNGM0OC05ODk0LWUwMjM3MzEwZjMwMyJ9.ge6RW8waAIzCTM14M_JfVNGKTgarWTgcrQBaTGeygjPqj2FftYTaev8P8p90A33GxvyHt2Ic6LCG6TmkHQ_BMQ6.解决跨域
(1) 服务器设置CORS响应头,
- 简单请求:
- 1.属于get post head(遇不到)
- 2.head仅包含安全的字段(不能包含任何自定义的)
- 3.请求头如果包含
Content-type,必须属于text/Palin、mltipart/form-data、application/x-www-form-urlencoded。同时满足三个条件才是简单请求
- 简单请求流程
- 1.简单请求在请求的时候会在请求头自动添加Origin字段,即页面的源地址
- 2.服务器响应头应该包含Access-Control-Allow-Origin
- 不是简单请求,则是需要预检的请求
- 1.浏览器发送预检请求,询问服务器是否允许(会自动附加三个消息头Origin、Access-Control-Request-Method(一会真实的请求方法)、Access-Control-Request-Headers(一会真实请求需要携带的请求头))
- 2.服务器允许,响应头应该包含Access-Control-Allow-Origin、Access-Control-Request-Method、Access-Control-Request-Headers、Access-Control-Max-Age(告诉浏览器多少秒内,对象相同的请求源、方法、头不需要再预检了)
- 3.浏览器发送真实请求(跟简单请求一样了)
- 4.服务器完成真实响应
- 带身份凭证的请求
- 如果跨域的话不会自动带cookie,如果还需要带则需要对请求方法配置额外的参数。
- 服务器在预检的时候,返回需要带 Access-Control-Allow-Credentials:true,否则都认为预检失败
- 这种情况下,服务器不能设置Access-Control-Allow-Origin设置为*
(2) nginx代理,基本上都是反向代理(部署在服务端)
(3) JSONP
- 需要浏览器和服务器打配合
- 跨域的时候不适用AJAX,转而生成一个script元素请求服务器,而服务器不组织script元素的请求
- 服务器拿到请求后响应一段js代码,实际上是一个函数调用,调用客户端预先设置好的函数,并把客户端需要的数据作为参数传递到函数中,从而简介的把数据传递给了客户端。
// 客户端
function jsonp(url) {
const script = document.createElement("script");
script.src = url;
document.body.appendChild(script);
script.onload = function () {
script.remove();
};
}
// 和服务端约定好的函数名
function callback(data) {
console.log(data);
}
jsonp("http://localhost:5008/api/student");
// 服务端
const express = require("express");
const app = express();
const port = 5008;
app.get("/api/student", async (req, res) => {
const result = {data: '学生数据'};
const json = JSON.stringify(result);
const script = `callback(${json})`;
res.header("content-type", "application/javascript").send(script);
});
app.listen(port, () => {
console.log(`server listen on ${port}`);
});7.输入url地址后
- 浏览器自动补全协议、端口(http=>80、https=>443)
- 浏览器自动完成url编码(中文转url编码)
- 浏览器根据url地址查找本地缓存,根据缓存规则看是否命中缓存。若命中缓存使用缓存,不再请求
- 通过DNS解析找到服务器的IP地址
- 浏览器想服务器发出建立TCP链接的申请,完成三次握手后,连接通道建立
- 若使用了HTTPS协议,还会进行SSL握手,建立加密信道。使用SSL握手时会确定是否使用HTTP2
- 浏览器决定附带哪些cookie到请求头中
- 浏览器自动设置好请求头、协议版本(http1还是2)、cookie,发出get请求
- 服务器处理请求,进入后端处理流程。然后服务器响应一个HTTP返回给浏览器。
- 浏览器根据使用的协议版本,以及Connection字段的约定,决定是否要保留TCP链接
- 浏览器根据响应状态码决定如何处理这一次响应
- 浏览器根据响应头中的Content-Type字段识别响应类型,如果是text/html,则对响应体的内容进行HTML解析,否则作其他处理
- 浏览器根据响应头的其他内容完成缓存、cookie的设置
- 浏览器开始从上到下解析HTML,若遇到外部资源链接,则一并请求资源(比如一个网页请求下面还有图片jscss请求等)
- 解析过程中生成DOM树、CSSOM树、然后一边生成,一边合并为渲染树,随后计算每个节点的位置的和大小(refloew),最后把每个节点利用GUP绘制到屏幕(repaint)
- 解析过程中还会触发一系列的事件,当DOM树完成后会触发DOMContentLoaded事件,当所有资源加载完毕后会触发load事件
8.文件下载
文件下载的消息格式
只要在响应头中加入Content-Disposition: attachment;filename='xxx'即可触发浏览器的下载功能。attachment表示附件,浏览器看到这个字段自动下载,filename表示浏览器保存文件时使用的默认文件名。
启用迅雷下载
如果浏览器安装了迅雷插件
<a data-res='thunder' href='http://localhost:8080/download/Wallpapar1.jpg'>下载壁纸</a>
<script>
const links = document.querySelectorAll('[data-res=thunder]')
for(const link of links){
const base64 = btoa(`AA${link.href}ZZ`)
a.href = `thunder://${base64}`
}
</script>9.TCP协议
TCP收发数据流程
- 建立连接(三次握手)
- 收发数据
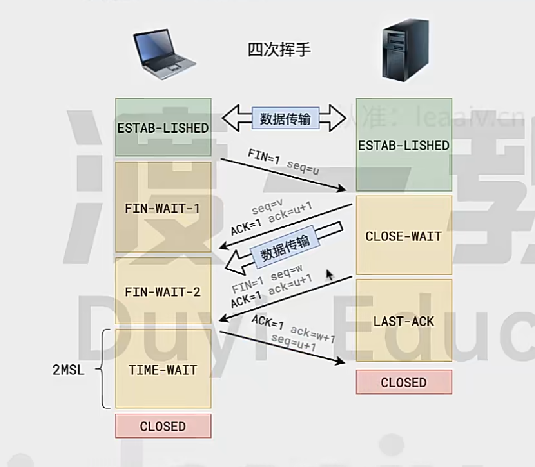
- 销毁连接(四次挥手)
收发数据
- 分段发送:分为数据报,每一段都是有头 + 内容组成
- 可靠传输:接收方收到数据报以后必须对数据报进行确认,从左到右发送
seq = x,从右到左返回ACK=1,ack=x+1 - seq 表示这次数据报的序号,ACK 表示这次数据报是一个确认数据报,ack 表示下一次希望接受的数据报序号
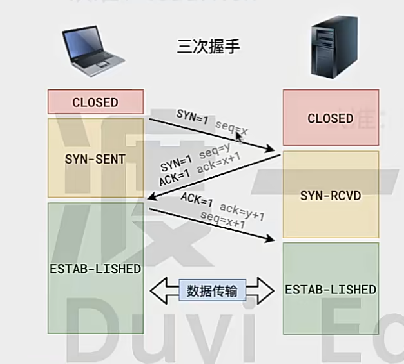
连接的建立(三次握手)
- A2B:你听到我了嘛
- B2A:我听到了,你听到我了嘛
- A2B:我也听到了
连接的销毁(四次挥手)
- A2B:我要关了
- B2A:ok我知道你要关了
- B2A:我也要关了
- A2B:ok我知道你关了
HTTP和TCP的关系
- HTTP对内容进行组合
- TCP负责消息的传输
- 虽然TCP可以相互发送消息,但是HTTP只能客户端请求,服务端响应
- 每一个HTTP请求-响应,都需要三次挥手,请求-响应,四次挥手
10.CSRF攻击
跨站请求伪造(Cross-site request forgery)。比如用户登录过某个银行网站,存在cookie,当你点击了钓鱼网站以后,会响应返回一个<img src='www.bank.com/transfer' style='display:none' />,src就执行转账接口带着你的cookie转账了。如果是post请求就用:
<form action="www.baidu.com" method="post">
<input type="hidden" name="to" value='11111'>
<input type="hidden" name="to" value='10000'>
</form>
<script>
document.querySelector('form').submit();
</script>
<!-- 然后在嵌入iframe -->怎么解决:
- 不使用cookie,但是兼容性略差,老系统没有localStorage
- 浏览器使用sameSite,容易挡住自己人
- 使用csrf token,每次回话都生成一个临时的token,生成token后未进行操作仍然会被攻击
11.XSS攻击
跨站脚本攻击(Cross Site Scripting),是指攻击者利用站点的漏洞,在表单提交时,在表单内容中加入一些恶意脚本。
怎么解决:
- 服务器端对提交内容进行过滤,去掉危险的标签和危险的属性
- 服务器端对提交内容进行实体编码,变成了字符串
12.断点续传
下载
主要是后端处理这个东西,在下载的时候会创建一个临时文件,用来记录当前文件下载到哪一段了,每一段文件下载好以后就更新内容,全部下载完了就组装为一个完整的文件。服务器给客户端响应的时候要添加消息头Accept-Ranges: bytes,客户端给服务端添加消息头range:bytes=0-5000(请给我传递0-5000字节范围内的数据)
上传
下载有统一的标准,但是上传没有,所以所有的代码都得自己写分片和组装。
客户端:
- 用户选择文件
- 把文件分割成多个分片
- 得到文件的MD5和每个分片的MD5(定长的字符串)
服务器:
- 对比还有哪些分片没有上传
- 上传没有上传的分片
- 循环12
- 直到全部上传就组包
举例:
// 调用
{
file:"md5",
type:".txt",
chunks:["md51","md52"]
}
// 其中md51+md52 可以还原为md5
// 返回
{
code:0,
msg:"",
data:["md51","md52"]
}
// 如果某个数据已经上传过,则不会返回这个md5存在的问题:并发问题,分片是不是按顺序上传
13.域名
- 根域名 .
- 顶级域名 .cn .com .net .us .uk .org 等
- 二级域名 .com .gov .org .edu 自定义 baidu jd taobao 等
- 三级域名 自定义 www.baidu.com www.jd.com
- 四级域名 自定义 www.pku.edu.cn 一般来说,购买二级域名后,三级、四级以后都可以免费自定义
DNS
域名解析服务器,域名转ip就叫做域名解析
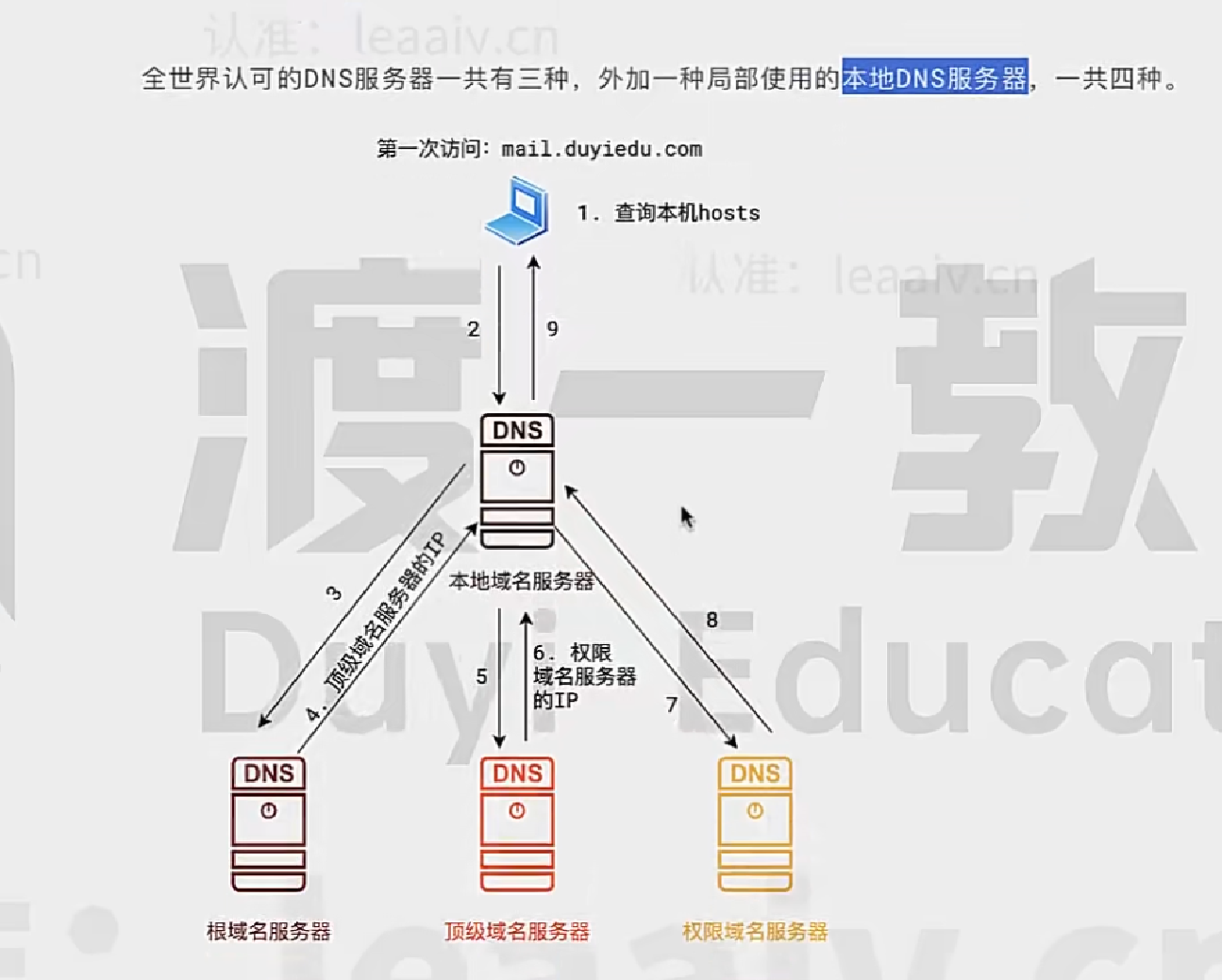
上述节点都可以设置高速缓存,减少查询次数和时间
- 本地域名服务器可以实现学校机房网站的隔离某些网站不让访问
- 当然最常规的还是走防火墙
14.SSL、TLS、THHPS
- SSL(Secure SOckets Layer)安全套接字协议
- TLS是SSL的升级版,两者几乎一样
- HTTPS是建立在SSL之上的HTTP协议
为了解决中间存在第三方拦截转发的问题,如果只是A和B交互,无论怎么使用对称非对称加密都是不行的。所以需要引入CA机构。机构使用私钥把域名和机构以及公钥用机构的私钥加密为证书签名。
面试:介绍HTTPS 握手过程
- 客户端请求服务器,并告诉服务器自身支持的加密算法以及密钥长度等信息
- 服务器响应公钥和服务器证书
- 客户端验证证书是否合法,然后生成一个会话密钥,并用服务器的公钥加密密钥,把加密的结果通过请求发送给服务器
- 服务器使用私钥解密被加密的会话密钥并保存起来,然后使用会话密钥加密消息响应给客户端,表示自己已经准备就绪
- 客户端使用会话密钥解密消息,知道了服务器已经准备就绪
- 后续客户端和服务器使用会话密钥加密信息传递消息
15.HTTP
HTTP1.0
- 无法复用连接(每个请求都需要三次握手四次挥手)
- 队头堵塞(上一个请求结束以后才能进行下一个请求)
慢启动:tcp在开始的时候速率很低,然后会指数型上升,再线性上升,触到网速峰值线性下降,然后再线性上升。
HTTP1.1
- 长连接,多次响应可以共享同一个TCP连接,也可以充分利用
慢启动 - 管道化(允许在响应到达之前发送下一个请求),但是依然没有解决队头堵塞的问题
- 缓存处理(新增响应头cache-control,用于实现客户端缓存)
- 断点传输
HTTP2.0
必须运行在安全模式之上
- 二进制分帧(HTTP2.0允许以更小的单元数据传输,每个传输单元就是帧,每一个请求或者响应的完整数据称为流,每个流都有自己的编号,每个帧都会记录自己所属的流。这就是多路复用)基于这个可以做很多东西,比如并行交替式传输;渐进式图片,越来越高清。
- 多路复用(基于二进制分帧,同域名下所有访问都是从同一个tcp连接中走,并且不再有队头堵塞问题,也无需遵守响应顺序)
- 头部压缩(客户端和服务器都有静态表,带冒号头部(:method:post)大概率来自于静态表,带冒号防止重名,静态表是一个键值对,bulabula编号为1、2、3等等。此外两方还有一个动态表,根据请求不断的新增内容)大概能减少20-30%的体积
- 服务器推流(客户端没有主动请求的情况下,服务器预先吧资源推送给客户端。当客户端后续需要请求该资源的时候,自动从之前推送的资源中寻找)
他也存在问题,解决不掉TCP的队头堵塞(比如我传输1、2、3帧的时候,2丢失了,TCP不敢传3,还需要等2重传)
HTTP3.0
- 转头使用UDP
- 安全问题使用QUIC协议
http1.1为什么不可以多路复用
- 因为接收方必须按序接受所有内容才可以接受下一个单元
- 正是因为按序接受造成了队头堵塞
- 队头堵塞导致了不可以多路复用
HTTP1.1如何复用tcp连接
客户端请求服务器的事后告诉服务器使用HTTP1.1的协议,同时请求头中附带connection:keep-alive(为保持兼容),告诉服务器这是一个长连接,可以后重复使用。
这么做的好处是减少了三次握手和四次挥手的次数,一定程度上提升了网络利用率。但是由于HTTP1.1不支持多路复用,响应顺序必须按照请求顺序抵达客户端,不能真正实现并行传输,因此2.0以前,实际项目往往把静态资源,比如图片,分发到不同的域名下的资源服务器,以实现真正的并行传输
16.websocket
websocket的握手
进行HTTP协议三次握手之后,再使用HTTP协议完成一次特殊的请求,就是websocket握手:
- 在握手阶段,首先客户端向服务器发送一个请求:
ws://mysite.com/path - 请求头如下:
Connection:Upgrade /*嘿,后续咱们别用HTTP了,升级吧*/
Upgrade:websocket /*我们把后续的协议升级为websocket*/
Sec-WebSocket-Version:13 /*websocket协议版本就用13好吗?*/
Sec-WebSocket-Key:YWJzZmFkZmFzZmRhYw== /*暗号:天王盖地虎*/- 服务器如果同意,响应头如下:
HTTP/1.1 101 Switching Protocols /* 101表示切换协议 */
Connection:Upgrade /*协议升级了*/
Upgrade:websocket/*升级到websocket*/
Sec-WebSocket-Accept:ZzIzMzQ1Z2V3NDUyMzIzNGVy /* 暗号:小鸡炖蘑菇*/- 握手完成,后续消息手法不再使用HTTP,任何一方都可以主动发消息给对方
websocket与传统http相比有什么优势
- 短轮询-展开说
- 长轮询-展开说
- websocket-展开说